Coupling between packages and end-to-end testing
Many organisations keep their code in multiple repositories which can create challenges when trying to develop using continuous integration.
Let me explain. imagine you have an embedded Linux system with some proprietary packages running on it: A web UI front end, a REST API that the Web UI talks to, various CLI tools and daemons that interact with the hardware.
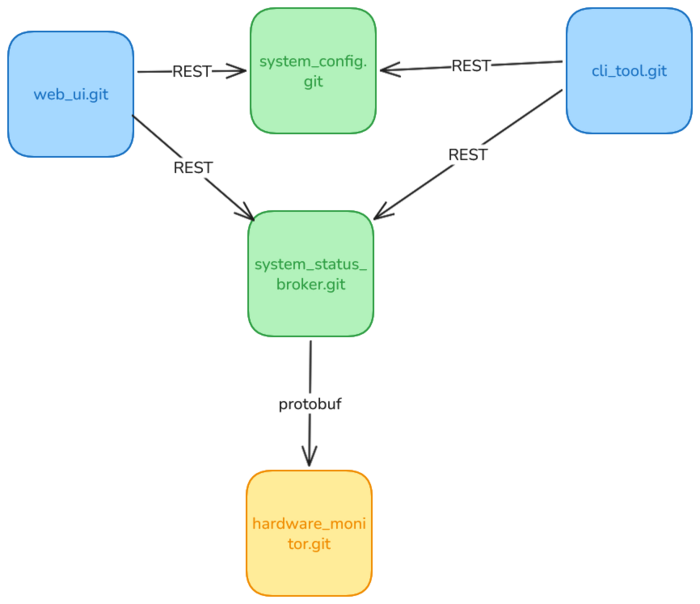
You develop each of these packages in their own repository and they have self-contained CI tests which use mocks for any interactions with other parts of the system.
The day comes that you realise the manual end-to-end build and test steps you're doing are not scalable. You need to set up a CI system that will build a system image and run end-to-end tests on PRs before they are merged.
But there's a big problem now because of coupled changes across repositories. You want to update the Web UI but it depends on a change to the REST API which is in a different repository. How do you test that? You have to make the CI build two PRs from different repos and combine them. How can you automate it?
Before I talk about some answers, a quick note about coupling. Coupling is where a piece of software depends on some other piece of software behaving a certain way. It is actually how all software works. But when most developers talk about coupling as a problem, they are referring to coupling that breaks application programming interface (API) contracts. APIs are how software systems can be coupled safely. Most of the time when I'm talking about coupling here, I'm meaning the general sense of two packages that interact, not necessarily breaking APIs.
Coupling of packages is not really unique to embedded Linux systems, it will happen in any end-to-end testing in CI when applications of multiple repos need to depend on each other. To solve the issue, you have three main approaches:
-
Migration through multiple commits: Make multiple commits using backwards compatibility. You add support for the new work but ensure it can still also work the old way. Then you upgrade the dependent system to make use of the new way, then you remove the support for the old way.
-
Orchestration and composition: An orchestration layer is introduced to your CI that can be made aware of dependencies between commits and configure the build to compose the PRs across multiple repos.
-
Use a monorepo: Anything that is causing coupling issues should just be put into one big repo. For an embedded Linux system, this would mean having your Yocto layer and proprietary applications all in the one repo with only a few independent and very stable packages staying in their own repos.
The downside of migration through multiple commits is that the commits all have to go through CI and get reviewed. It adds a lot of overhead to a potentially small change and depending on how slow your test and review stages are, it could be prohibitively expensive.
One theoretical benefit of migration through multiple commits is it creates a disincentive to couple changes together. Developers are challenged to avoid changing APIs where possible. In practice, this is impossible. Some repositories are naturally coupled - even if they are very different code bases e.g. you might have a C back-end and Javascript front-end in different repositories that are often dependent because some change in the back-end needs to also be reflected in the front-end.
Orchestration and composition is supported to some extent in CI tools. There is usually some facility to trigger other workflows and pass payloads between them but it always seems pretty fragile to me. The configurations are complex and seem to be add-ons rather than designed in from the start. In my experience it is not a reliable approach. If you're in a position where you are choosing which CI system to adopt, then put composability on a must-have features list.
Monorepos are the more traditional systems I've seen. They are the simplest case. There are a few disadvantages though:
- They become massive! The monorepo grows and grows and it's difficult to trim them back. Cloning them can take a very long time and use a lot of bandwidth if you're using cloud services.
- They enable code that breaks API boundaries. Once the barriers to coupled packages are removed, developers will start writing code that violates API design principles. Not on purpose but because of time pressures or by mistake. It is up to the senior engineers to now police the system with more vigilance or come up with some automated checks.
So what's the answer? I think it's a combination of the three options. A rule I've heard before is that "code that changes together should stay together". The idea is usually for architecture but it can apply to repository organisation as well. The default should be to isolate packages in their own repositories and build out a pretty flexible API early on so that ongoing changes are minimised. If the nature of the package is that it has to change in sync with another package more often than not, then consider merging the two repositories. Once you have packages sharing a repository, introduce review checklists and automation that alert or prevent developers from breaking APIs.